


Salesforce’s Spring ’25 release introduced a native Compression namespace in Apex (API v56.0 and later) to create and read ZIP archives without any external libraries. Whether we need to bundle generated content for download or process uploaded ZIP files, this feature makes it straightforward.
In this blog, we will learn:
- Prerequisites and setup for sandbox or production orgs
- How to compress one or more Blobs into a ZIP archive
- How to extract files from a ZIP archive
- Identifying directories correctly in ZIP entries
- A Simple example can run immediately
- Best practices and considerations
By the end, we will have Apex code ready to zip and unzip files in any org on API v56.0+.
Why is Native ZIP Support Important?
Before Spring ’25, handling ZIP files in Apex required third-party libraries or complex JavaScript, as well as different levels of remoting workarounds. Different levels of common challenges are included below:
- Dependency Management: Unmanaged packages added maintenance overhead and potential compatibility issues. For many orgs, initially, it’s a difficult and time-consuming process.
- Governor Limits: External services often meant round-trip callouts and slower performance.
- Security: Bringing in external code introduced additional security reviews and trust concerns. For anyone, org security will be in first place.
Native ZIP support removes these difficulties by providing:
- In-platform functionality with no external dependencies
- Efficient memory use through in-memory compression and extraction
- Simplified coding using straightforward Apex methods
Prerequisites
Before we start, we need to make sure of the following setup points:
- API Version
- All Apex classes that reference the Compression namespace must use API version 56.0 or higher.
- We can set this in the Developer Console or our IDE’s project settings.
- All Apex classes that reference the Compression namespace must use API version 56.0 or higher.
- Permissions
- The running user needs Author Apex to run custom code and Modify All Data to create or update ContentVersion or Attachment records.
- The running user needs Author Apex to run custom code and Modify All Data to create or update ContentVersion or Attachment records.
- Org Type
- This works in any sandbox or production org with API v56.0+. No scratch-org feature flags are required in non-scratch orgs.
- This works in any sandbox or production org with API v56.0+. No scratch-org feature flags are required in non-scratch orgs.
- Development Tools
- We can use the Developer Console or VS Code with Salesforce extensions for coding and execute Anonymous testing.
Compressing Files with Compression.ZipWriter
The Compression.ZipWriter class lets us construct a ZIP archive entirely in memory. We will be able to add one or more files each as a Blob under a specified name and then retrieve the combined archive as another Blob.
Key Steps
1. Instantiate the writer:
2. (Optional) Adjust Compression Method:
-
- The default is Compressed.
- For no compression (faster, lower CPU), use:
3. Add Files to the archive:
4. Generate the Archive Blob:
Persisting the ZIP Archive
Once we have a ZIP Blob, we will be able to store it in Salesforce using our preferred approach:
As a File (ContentVersion)
As a Classic Attachment
Use ContentVersion for Lightning Files, use Attachment only if you require an older version than the current model.
Extracting Files with Compression.ZipReader
The Compression.ZipReader class reads an existing ZIP Blob and exposes its entries. We can then extract each entry back into a Blob.
Handling Entries
Salesforce’s ZIP support does not include a different type of method. To detect folders inside the archive, check if the entry name ends with a forward slash (‘/’), which is the standard ZIP convention.
Example
Below is a self-contained Apex class that:
- Compresses one text file into a ZIP archive.
- Saves that ZIP as a File (ContentVersion).
- Retrieves the saved ZIP back.
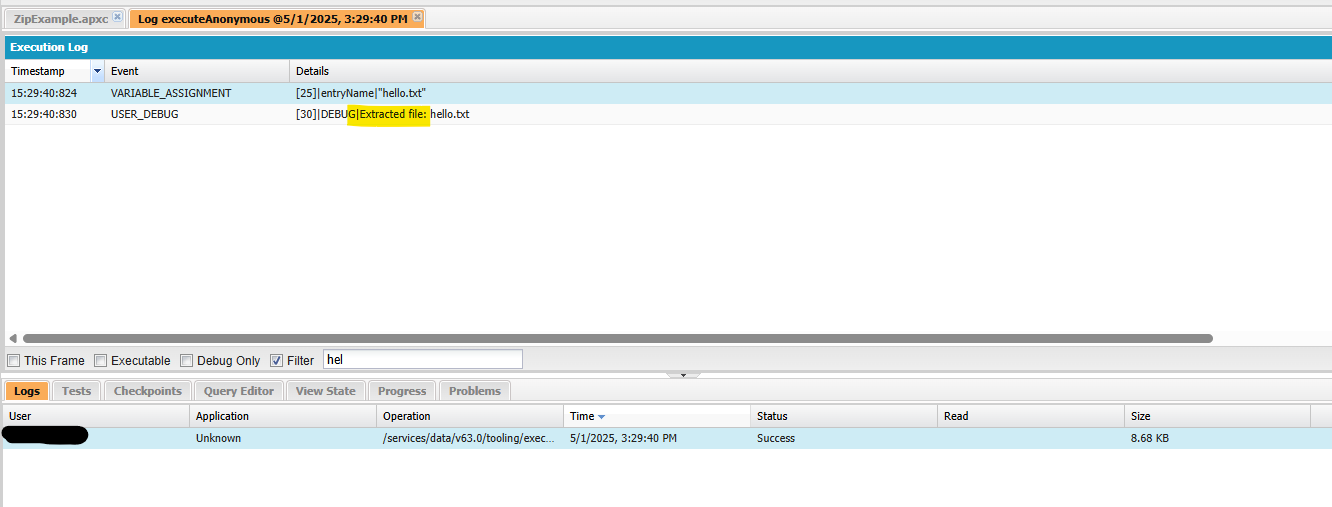
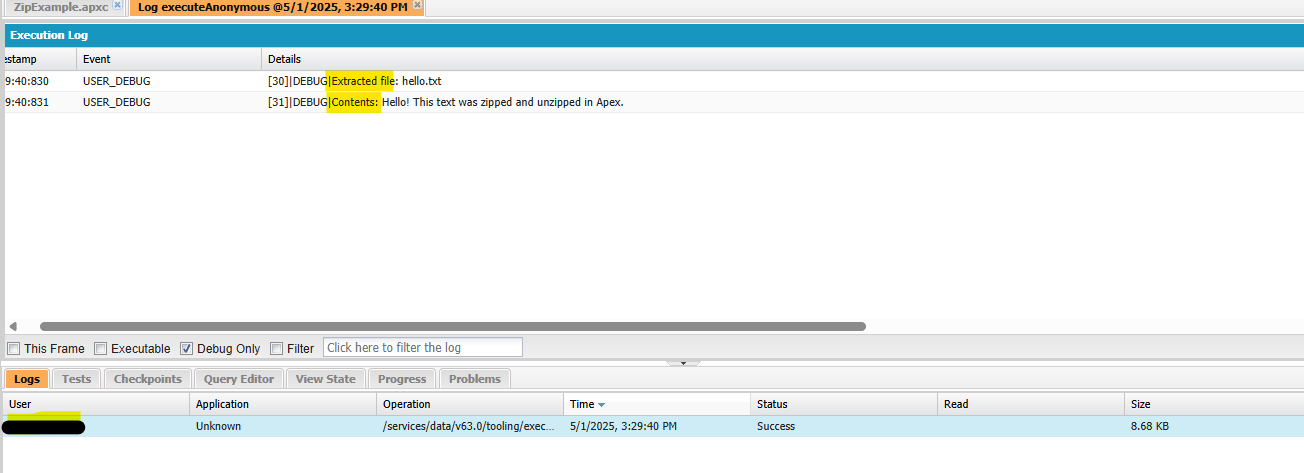
- Extracts the original text file and logs its contents.
How to Execute
1. Deploy the ZipExample class in your org (API v56.0+).
2. Open the Developer Console → Debug → Open Execute Anonymous Window.
3. Run:
4. Check Debug Logs:
We will be able to see logs confirming the insertion of ContentVersion, along with the extracted hello.txt and its message.
Also Read – Salesforce Summer ’25 Release Updates For Developers
Best Practices and Common Drawbacks
- API Version
Always set classes of our org to API v56.0 or later to access Compression. - Heap & CPU Usage
Zipping or unzipping very large Blobs can consume significant heap space and CPU time. For large archives, consider asynchronous processing (Queueable or Batch Apex). - Compression Method
- DEFLATED: Compresses data, smaller file size, more CPU.
- STORED: No compression, faster, lower CPU.
- Directory Detection
Check entry.getName().endsWith(‘/’) for folders, since there are no other methods. - Error Handling
Wrap ZIP operations in try-catch to handle corrupted archives or unexpected data properly. - Security
Only process trusted ZIP files. Clean entry names to prevent directory traversal or unexpected paths. - Persistence Choice
Always prefer ContentVersion for Lightning Files and user previews; we can use Attachment only when required by legacy or very old integrations.
Conclusion
The native Compression namespace in Apex simplifies ZIP archive handling directly within Salesforce with no external libraries needed. This guide provided:
- A clear overview of ZipWriter and ZipReader usage
- The correct way to detect directories in entries (by checking endsWith(‘/’))
- A single, streamlined example to zip a text file, save it as a File, and then unzip and log its contents
- Best practices for performance, security, and API versions
Always try a new functionality in sandbox or production org with the latest versions for a better experience and start compressing and extracting ZIP files natively in Apex today! Happy Coding.




