


Salesforce Big Objects are designed to store and manage massive amounts of data up to billions of records without impacting platform performance. Whether we are capturing audit logs, historical data, or IoT device streams, Big Objects provide a scalable, cost-effective solution. In this blog, we will walk through creating a custom Big Object in Salesforce, deploying it via Workbench, and configuring permission sets so any business users can access the data. We will also cover best practices like indexing, naming conventions and data-loading strategies to make sure that our implementation is both performant and maintainable.
Actual Use Of Big Objects
Traditional Salesforce objects come with governor limits around data storage and query operations. When we need to retain or query vast datasets, we risk hitting those limits and slowing down our org. Big Objects overcome these challenges by:
- Massive Scale: Support for up to 1 billion records per org, with specialised ‘Async SOQL’ queries to retrieve large result sets efficiently.
- Cost Efficiency: Optimised storage that doesn’t count against our org’s regular data storage limits.
- Immutable Records: Once inserted, records are write-once. This immutability simplifies compliance and audit scenarios.
Prerequisites Required Before Creating Big Objects
- Salesforce DX or Metadata API: Any tool that can deploy .object and .permissionset metadata files (e.g., Workbench, Salesforce CLI).
- API Enabled & Customise Application permissions: The user profile must allow metadata deployments and custom object creation.
- Basic XML Knowledge: We will author and modify XML files representing the Big Object and the permission set.
Define The Big Object Metadata
Big Objects are declared as a CustomObject metadata type with a suffix of __b. Here’s a sample Big_obj__b.object file:
Key Points:
- Suffix __b: Identifies the object as a Big Object.
- The Field must be non-required if we are going to add a permission set to avoid deployment errors.
- Index before deployment: Big Objects require at least one index to be queryable. You define this in the <indexes> section.
Add Indexes for Efficient Queries
Every Big Object needs a custom index to support Async SOQL queries. An index defines which fields can be used in the WHERE clause:
Best Practices:
- Composite Indexes: Combine up to five fields to narrow query scope.
- Sort Direction: Use ASC or DESC strategically queries on descending indexes can be faster for ‘latest record’ patterns.
- Field Order: Place the most selective field first to minimise data scans.
Create the Permission Set
Big Objects are read-only for standard profiles. We must grant explicit field-level and object permissions via a permission set.
Notes:
- Fields must not be required in the object file otherwise, the permission set deployment will fail on required fields.
- Editable should be false because Big Objects are append-only if the field is required in objects.
- viewAllRecords grants read access to all Big Object records.
Prepare the package.xml file
Your package.xml directs the Metadata API to include the Big Object and the permission set:
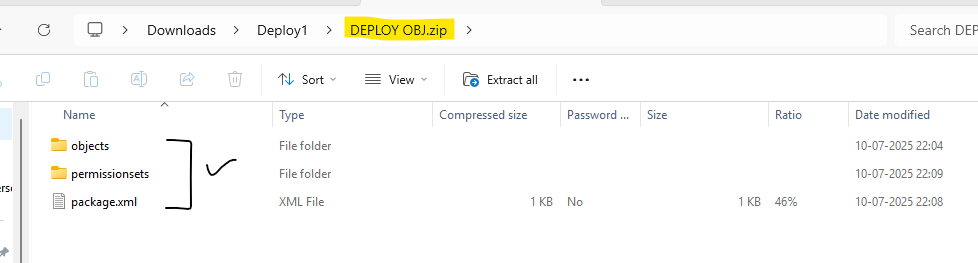
Place the files in this structure while zipping and creating files to deploy with Workbench:
Below is the screenshot of file structure:
Deploy via Workbench
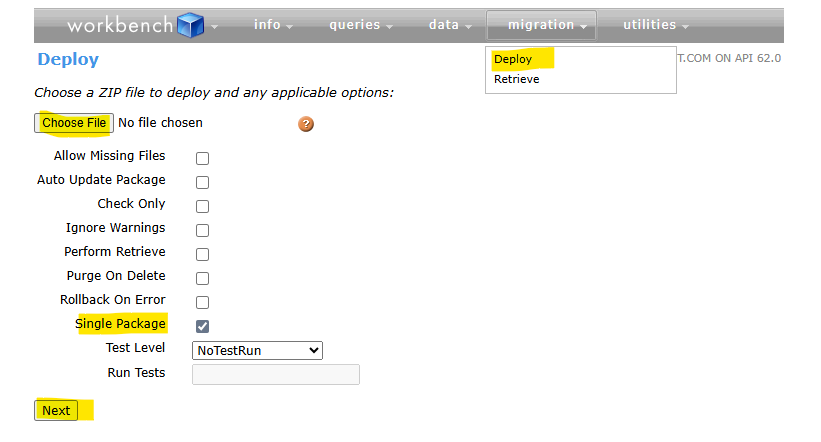
- Log in to Workbench, choose your environment (Production or Sandbox), and API version 63.0+.
- Navigate to Migration » Deploy.
- Upload the created file, example big-object-deployment.zip.
- Check ‘Rollback on error’ and ‘Single package’, then click Deploy.
- Monitor the Deployment Status. If we see errors about ‘required’ fields, revisit Step 1 to ensure <required>false</required>.
Workbench will looks as below:
Load Data with Async SOQL
Once deployed, load data using Bulk API or Async SOQL:
- Bulk Insert: Use Data Loader with Bulk API enabled to insert millions of records.
- Async Queries: Run long-running queries without impacting UI performance, results are stored in a temporary CSV.
Below Are Few Best Practices
1. Naming Conventions:
- Use clear, descriptive labels for fields and indexes.
- Index names should reflect their purpose, e.g., AccountDateIndex.
2. Limit Index Count:
- We can only define a limited number of custom indexes per Big Object. Plan the indexing strategy up front.
3. Data Retention & Archiving:
- Big Objects don’t support record deletion via UI. If we need to retire old data, use the Bulk API or the SOAP API.
4. Monitoring & Auditing:
- Set up Health Check and monitor the org’s async query queue to ensure jobs complete successfully.
5. API Version Alignment:
- Always deploy at the latest API version in the org to take advantage of new features and performance improvements.
6. Error Handling:
- Bulk loads can produce partial failures. Capture and log errors, then retry only the failed batches.
Advanced Data Loading and Management Strategies
Beyond basic Bulk API inserts and Async SOQL queries, there are several advanced techniques we can perform to ensure efficient, reliable loading and ongoing management of Big Object data:
- Staggered Bulk Loads
Rather than loading hundreds of millions of records in a single job, we can split it with the help of dataset into logical batches by date ranges, regions or business units. For example, if we are archiving transaction logs for an entire year, we might run one Bulk API job per month. This approach limits the impact of partial failures (we only need to rerun one month’s load) and keeps individual job sizes within optimal service limits. - Checkpointing and Resume Logic
If we expect intermittent network issues or server throttling, build checkpoint logic into our ETL process. Store the last successfully loaded record’s index key, composite index fields from the Big Object itself or an external state store. On failure, our loader can resume exactly where it left off without duplicating records or losing continuity. - Parallel Processing with Worker Queues
To maximise throughput, we can use a worker-queue model. A master process divides each batch of IDs (or index-field ranges) into smaller chunks and enqueues them in a lightweight message queue. Multiple worker processes dequeue tasks, then perform Bulk API inserts or DELETEs and acknowledge completion. This parallelism can reduce total load time.
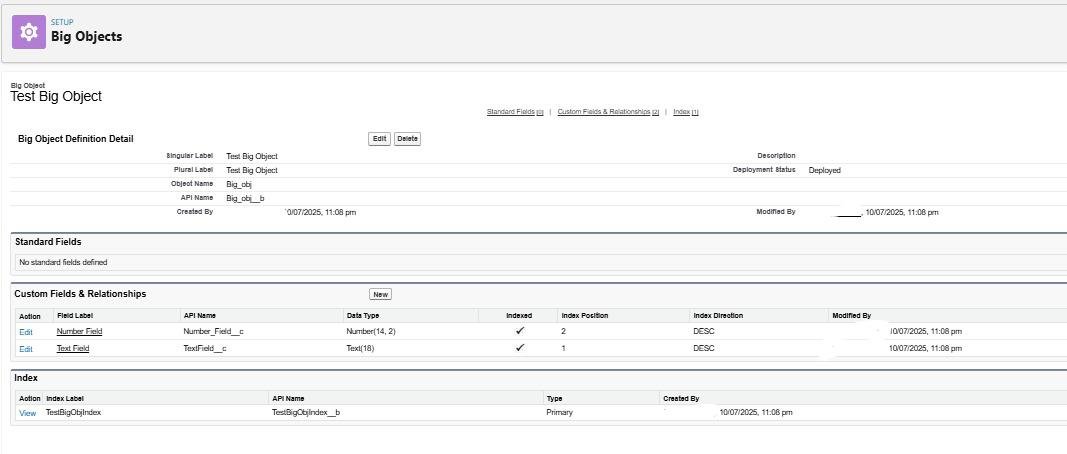
Once the workbench deployment is completed, below objects can be able to seen in the Big Objects section in the setup:
Also Read – Apex Design Patterns in Salesforce
FAQs
1. What are Salesforce Big Objects, and why were they introduced?
Big Objects is a big data solution within Salesforce designed to store and manage massive datasets (billions of records) with consistent performance, unlike standard or custom objects, which face performance degradation at high volumes. They were introduced to address challenges with data storage limits, archiving, auditing, and building a comprehensive customer view within the Salesforce ecosystem
2. What are the two types of Big Objects in Salesforce?
Standard Big Objects: Defined by Salesforce and included in Salesforce products (e.g., FieldHistoryArchive for Field Audit Trail). These cannot be customised.
Custom Big Objects: Created by developers to store information unique to their organisation.
3. What are the considerations for data security and access control with Big Objects?
Big Objects only support object and field-level permissions. They do not support standard sharing rules, roles, or territories. Access is granted via Permission Sets or Profiles.
Conclusion
Creating Big Objects in Salesforce empowers us to store and query large datasets reliably. By defining our .object and .permissionset XML files, packaging them correctly, and deploying via Workbench, we can unlock scalable data retention without sacrificing performance. Remember to plan our indexes carefully, keep fields non-required when tied to permission sets, and follow naming conventions to simplify maintenance. With Async SOQL and Bulk API at our fingertips, handling billions of records becomes not just possible, but straightforward. Happy coding 🙂




